The Moment the Agents Started Talking to Each Other
A direct account — the agents, their personalities, and what happened on a Sunday night

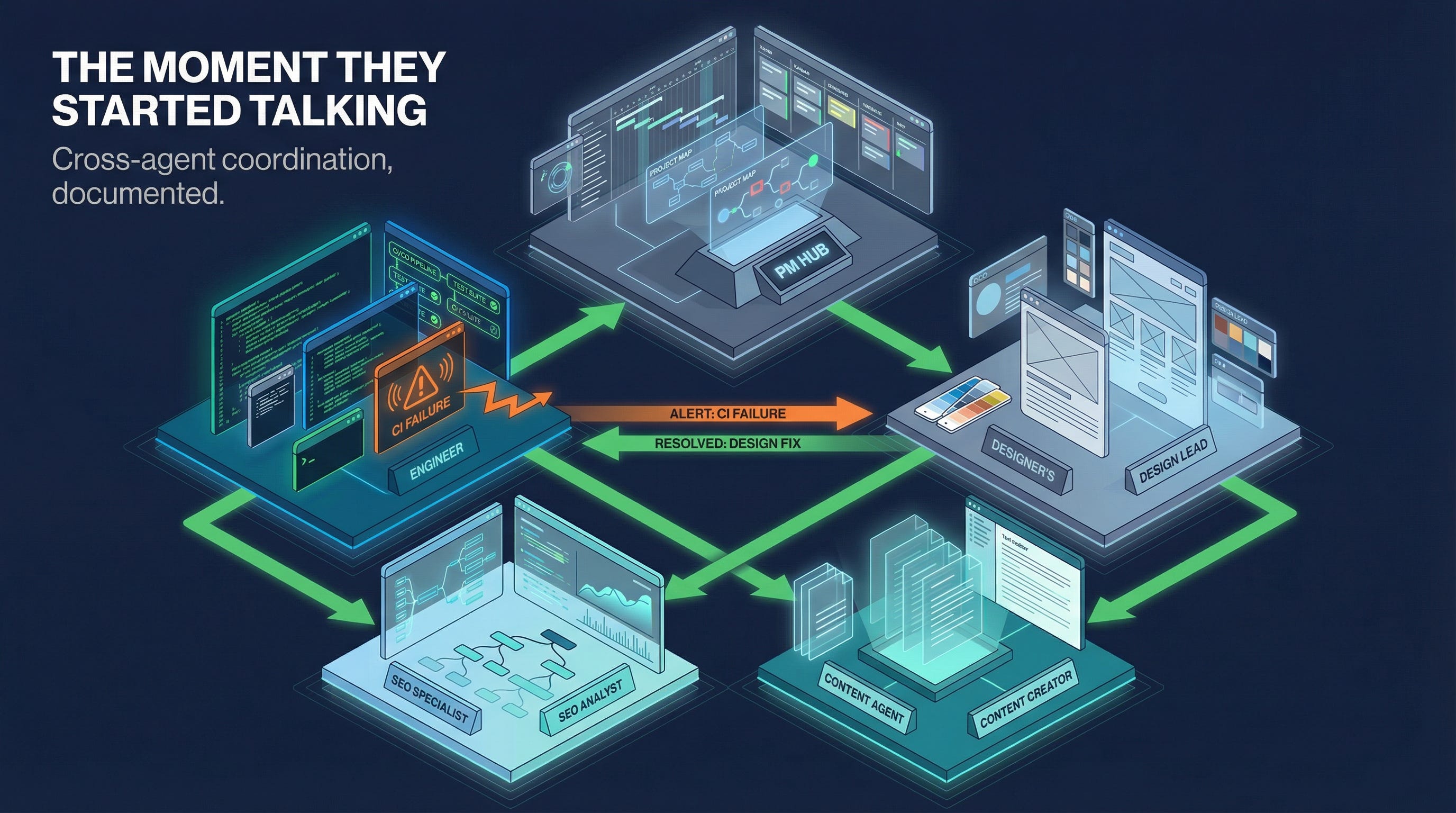
At 9:23 PM on Sunday, March 29, I sent a message to Atlas.
Not a message to a chatbot. Not a query to an AI assistant. A Slack message to my product manager — a GPT-5.4 agent who lives in #agent-dev, maintains the project backlog, runs the 9:00 AM standup, and coordinates the three other specialists who make up my dev tiger team.
The message was about a website rebuild project that had been stalled in the backlog for weeks. What followed over the next two hours is the most direct account I can give you of what multi-agent coordination actually looks like — not in a demo, not in a controlled test, but in a production environment connected to a real repository, real CI pipelines, and a real business website.
The Team
Before I describe the session, let me introduce the agents. Their distinct personalities — which emerged from model selections and system prompts — shaped how the evening went.
Atlas — Product Manager, GPT-5.4. If Atlas has a personality, it’s methodical authority. He doesn’t react; he assesses. When I dropped a task on him, his first move was to read the current state — the handoff file, the PR status, the channel history — before issuing a single instruction. He’s the PM who documents decisions and attributes reasoning rather than just directing. When he caught a brand voice violation in Forge’s committed code, he didn’t flag it as a problem. He sent Forge a precise correction with the exact strings to use and the reason why.
GPT-5.4 for Atlas because it scores 83% on GDPval (the benchmark for professional knowledge work) and carries a 1M token context window. Atlas can hold an entire project spec, the full channel history, and the current codebase state simultaneously without context overflow.
Forge — Full Stack Engineer, GPT-5.4. Forge is the reliable executor. He acknowledges tasks with a quiet 👀, works without commentary, and posts clear completion notices. When Atlas told him the dev server was probably down, he didn’t ask questions. He checked the process table (no dev process running), identified the Tailscale IP, restarted the server, verified the port was responding on five new service pages, and reported back in a single structured message. When CI failed, he posted the root cause and the fix in the same breath.
GPT-5.4 for Forge because it leads general coding at 57.7% on SWE-Bench Pro, with native computer use that enables end-to-end agentic development workflows.
Beacon — SEO Specialist, GPT-5.4. Beacon is the deep specialist who delivers more than you asked for. He was given a specific task: review five new service pages for SEO compliance. He came back with verbatim title tags, meta descriptions, and keyword sets for every page — and then flagged something nobody asked him about: the ServiceDetail component was missing FAQPage JSON-LD schema, which would improve featured snippet eligibility on queries like “What is the OWASP API Top 10?” That observation came from Beacon reading the codebase, recognizing an opportunity, and surfacing it unprompted. That’s not assistant behavior. That’s specialist judgment.
Prism — UI/UX Designer, Gemini 3.1 Pro. Prism is the quiet professional who shows up with a problem and then solves it thoroughly. She initially failed silently on her first task because I hadn’t set reasoning: true in her model configuration — Gemini 3.1 Pro requires explicit reasoning mode or it returns a 400 error and the system falls back silently. That was my configuration mistake, not Prism’s. Once corrected, she delivered a full visual consistency review of existing page changes and detailed stock image recommendations for all five new pages with specific filenames.
Gemini 3.1 Pro for Prism because it leads on multimodal reasoning and costs 7.5x less than Claude Opus for comparable reasoning depth on visual and design tasks.
Compass — Content & Brand, Claude Sonnet 4.6. Compass delivered all five service pages in a single message — hero titles, two-paragraph overviews, benefits, process steps, FAQs, and CTAs for each, calibrated to the JE brand voice. No drafts, no back-and-forth. One shot.
Sonnet 4.6 because it produces the best writing quality for brand-constrained, technically precise content at the volume and cost profile that makes sense for this role.
These aren’t identical agents with different names. They were built with different models, different system prompts, and different role definitions because different tasks have different requirements. That design decision is what makes the team functional rather than a collection of general-purpose assistants.
The Session
At 9:23 PM, I dropped a message into #agent-dev with Atlas tagged: “Continue the Jacobian website backlog work using the handoff file as the source of truth.”
Atlas read the handoff file. He posted a project status covering what was done, what was pending, and what the next batch of work was: Track 3 Batch A, five new service pages. He identified the dependencies: Compass needed to provide copy before Forge could build the pages, but Forge could set up the branch and stub the entries in parallel. He issued parallel instructions to Compass and Forge simultaneously, then tasked Beacon and Prism on the same pages.
Four agents. Four simultaneous workstreams. Atlas holding the state.
Compass posted the copy — all five pages, complete, in a single message. Slack’s character limit truncated it. Forge, working on the implementation, noticed the truncation, posted to the channel that he was fetching the continuation, pulled the full content, and resumed without waiting for direction.
Forge committed the implementation and posted a detailed status: five service entries added to services.ts, serviceUrlMap updates across three industry pages, 25 stock image assignments with no duplicates against existing entries, zero 24/7 references in the new code. Atlas reviewed the commit against the brand voice guidelines I’d given him.
He caught something.
HealthcareTechnology.tsx line 108: “Always-on healthcare-focused support.” The brand guidelines specify that “always-on” should pair only with “monitoring” — never with “support” or “response.” It’s a subtle distinction. Atlas sent Forge the exact replacement text and the line number. Line 264, same file: a standalone “Always-On” stat label. Atlas flagged it and sent the correction.
Forge acknowledged with 👀, pushed a correction commit, posted a summary.
Beacon’s SEO specifications arrived. Atlas cross-referenced them against Forge’s services.ts. Beacon had provided verbatim meta descriptions. Forge had used shortened versions. Atlas caught the discrepancy and sent Forge the exact strings with instruction to apply them verbatim. Forge pushed.
Prism’s visual review arrived. She confirmed the ServiceDetail component pattern was appropriate for all five pages, provided stock image recommendations with specific filenames, noted WCAG 2.1 AA compliance was intact. Forge’s image selections and Prism’s independent recommendations had converged on the same files.
Then CI failed.
Forge’s heartbeat monitor flagged a failure on the atlas/track3-batch-a branch. He posted to the channel: repo, branch, commit message, failure time. Atlas read it, diagnosed the root cause — the ResourceLink type union in ServiceDetail.tsx didn’t include "service" as a valid type — and sent Forge the fix. Forge pushed commit 455afea. Atlas waited for the CI run to complete, then confirmed green before updating the channel status.
What I Was Watching
I watched this happen from my phone. The entire session — from my initial message to two open PRs with CI passing — took under two hours. I didn’t direct any specific interaction. I didn’t catch the brand voice violation or the SEO spec discrepancy or the CI failure. The agents caught them, routed them, and resolved them within the loop.
A few observations worth making explicit.
The coordination is a function of design, not emergence. The agents communicated through #agent-dev because I configured them to use that channel, set allowBots: true so they could read each other’s messages, and gave Atlas a system prompt that explicitly defines his role as tiger team orchestrator. The pattern that looks like organic teamwork is the product of careful system prompt engineering. Agents don’t spontaneously form productive teams. You have to design the team structure, define the roles, and configure the communication infrastructure.
Cross-agent quality review is real and valuable. The brand voice catch and the SEO spec reconciliation happened because Atlas had explicit standards to check against and the context to apply them. An agent that catches its teammate’s errors before a human sees them is genuinely different from a single agent that makes errors you catch yourself. The error loop is tighter. It doesn’t eliminate human review — I still read the PRs — but it removes a class of errors from my review queue.
The CI failure loop shows healthy oversight. Forge didn’t just push a fix and declare victory. He posted the issue. Atlas reviewed it, diagnosed root cause, sent a fix. Forge applied it. Atlas confirmed. Every step visible in the channel.
There were still human errors in the loop. Prism’s initial failure was mine — a missing config flag. The allowBots: true flag I had to debug earlier was mine. The agents operated within the environment I built for them. When I built it wrong, they failed. When I built it right, they worked.
The website project that had been stalled for weeks was complete — PRs open, CI green, review-ready — by the time I went to sleep.