Claude Agent Series: What the Bug Was Actually About
The technical root cause was one flag. The real subject was something harder: what you can’t see when you’re inside the system looking out.

I’ve spent four posts on the mechanics of a production debugging session. The leaked tokens, the wrong hypotheses, the file-based IPC between two Claude instances, the git archaeology that explained why the trap sat dormant for sixteen days. The technical account is complete.
Now I want to tell you what I think the session was actually about.
It wasn’t about the flag. It was about observability — specifically, the absence of it — and what happens when an AI system has real operational authority but no sensors pointed at its own behavior.
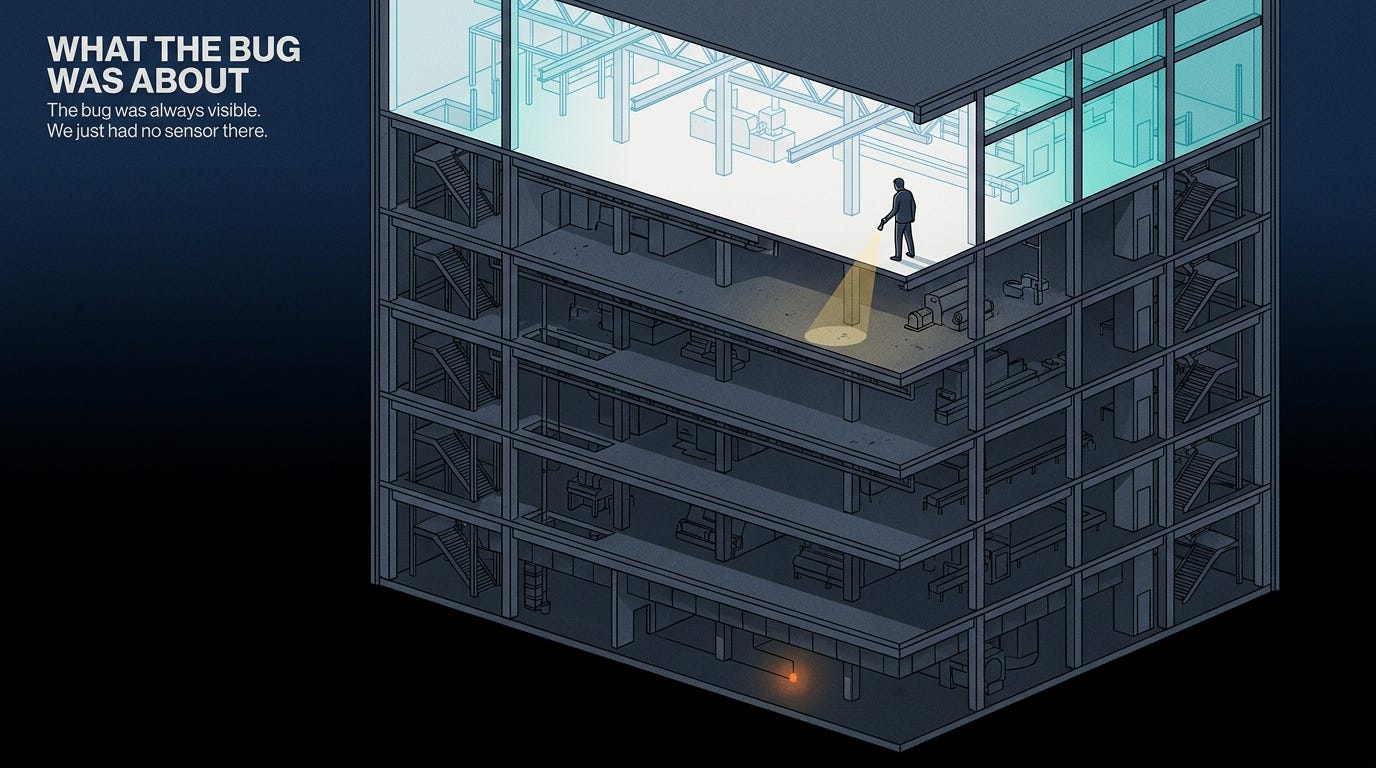
What we were missing
For the first six hours of focused debugging, neither drclaw-Claude nor I could see the vLLM container. We could see Compass’s Slack output. We could see the Mem0 memory collection. We could send curl requests to the inference endpoint and observe responses. What we couldn’t see: the raw SSE stream between OpenClaw and vLLM, the per-request sampling decisions, the inference logs, which code paths were being invoked, which weren’t.
Everything we concluded in those six hours was inference from downstream artifact. The reasoning was often sound. The hypotheses were often plausible. And they were wrong, serially, until we built the sidecar.
The sidecar took about forty minutes to specify and build. Starlette, httpx, byte-exact passthrough, port 8001, filtered to the drclaw Tailscale IP. After it was live, every hypothesis became testable. The chunk-split theory: falsified in twenty minutes. The feedback-loop theory: falsified by the minimal-environment replay. The token-ID string-match theory: falsified when the [GEMMA4_DBG] tags produced zero log lines.
Six hours of stalled investigation followed by ninety minutes of systematic falsification, once measurement existed.
That ratio should be familiar to anyone who’s debugged production systems. The hard part isn’t usually the fix. It’s building the lens that lets you see where to look.
The agentic layer adds a new version of this problem
I’ve been running a multi-agent AI fleet in production for about a year. The agents handle real operational tasks: marketing content, system monitoring, project management, content publishing. They have real authority: they can send Slack messages, write to Notion, restart services, execute shell commands under a configured security profile.
The standard observability toolkit for these systems — logs, metrics, traces — doesn’t tell you what you actually need to know about agent behavior. It tells you whether the infrastructure is healthy. It doesn’t tell you whether the agent’s reasoning is on track, whether a hypothesis has been stuck in its context window for four hours, whether it’s about to execute a task based on a memory that doesn’t belong to it.
The content-delta leak was visible because it produced a malformed Slack message. That’s lucky — it left an artifact. Most ways an agent can be “wrong” don’t leave an artifact. They leave a task half-done, a decision made on bad context, a communication sent with outdated information. You find out downstream, when someone asks why something happened.
The fleet I run has seven agents. Each one has a conversation history, long-term memories, access to external tools, and the ability to spawn sub-agents for complex work. The observability surface for all of that is: Slack messages, Notion records, logs on the EC2 instance, and my own attention. When something goes wrong, I’m usually working backward from an output that looks wrong, trying to reconstruct what the agent was reasoning when it produced it.
That’s the same position drclaw-Claude was in when the leak surfaced. Working backward from downstream artifact. Guessing at the upstream cause.
What better observability would look like
I want to be specific here, not aspirational.
The sidecar we built was an ad-hoc answer to an acute problem. A permanent version of it — a request/response logger between OpenClaw and vLLM, running continuously, queryable by time window and agent — would have cut the debugging session from six hours to twenty minutes. The leak body would have been captured on the first occurrence, two weeks before the session, before anyone noticed the Slack messages. The problem would have been a maintenance item, not a crisis.
That’s the first instrument: wire-level request/response logging on the inference layer. It exists for web services. It doesn’t exist by default for local inference stacks. It should.
The second instrument is harder: reasoning trace logging at the agent level. When an agent generates a hypothesis and acts on it, what was in its context? What memories were active? What tool calls were being planned? The standard conversation log captures the assistant’s final output. It doesn’t capture the intermediate reasoning that produced it. For debugging, the intermediate reasoning is usually what matters.
Claude’s extended thinking mode produces something close to this — a structured chain-of-thought that can be logged and inspected. The agents in my fleet run on Gemma 4 (a local model) for most workloads, and enabling actual thinking mode on Gemma 4 is a Phase 3 project that’s planned but not yet deployed. For the cloud-model agents (Atlas on Opus, Scholar on Gemini Pro), it’s available today.
The third instrument is what I’d call a hypothesis monitor: something that can detect when an agent is circling. When the same theme has appeared in the last N turns without resolution. When the evidence gathered hasn’t updated the working theory. This is harder to define precisely and probably requires something beyond simple pattern-matching on the context. But the functional requirement is clear: I want to know when an agent has been stuck for a while, not when it gives up or produces an error.
The trust architecture
There’s a different way to look at the authorization ladder — the sequence of permissions I granted over twenty-one hours.
At 00:18: build and cherry-pick. At 03:25: install the tarball. At 04:09: reboot. At 04:22: execute the Mem0 wipe. At 04:30: generate SSH keypair. At 05:08: restart OpenClaw any time, direct the DGX agent to restart vLLM. At 12:36: deploy Phase 1 and 2.
Each grant extended what the agents could do without interrupting me. The grants were conditional on demonstrated behavior at each prior level. The Mem0 wipe at 04:22 was interrupted after the fact by new data — not because I withdrew trust, but because the situation changed. The 05:08 grant — broad operational autonomy while I slept — was made because I’d watched drclaw-Claude operate carefully for nine hours.
This is how trust should work between humans and AI systems that have operational authority: incrementally, based on demonstrated judgment, with clear constraints on blast radius at each level. It’s also the structure under which this particular debugging session played out most of its productive work. The agents fixed the bug while I slept.
What makes that possible isn’t the AI’s capability in isolation. It’s the combination of capability, constrained authority, observable behavior, and a human who’s watching and willing to interrupt. Remove any one of those and the picture changes. A capable agent with unconstrained authority and no observability is a different risk profile than what I was running.
The Mem0 wipe deleted eleven legitimate memories. The session file strips accomplished nothing. The wrong-layer patch was technically correct about the wrong code path. Those are real mistakes, made by an AI system operating with real authority. The mistakes were recoverable because the blast radius was constrained and the behavior was observable.
What Phase 3 actually represents
At the end of the session, drclaw-Claude wrote a Phase 3 plan: how to actually enable Gemma 4 thinking mode correctly. chat_template_kwargs.enable_thinking: true. skip_special_tokens: false. The correct jinja template. The complete stack from client config to inference flags.
The capability was available the whole time. It’s documented in the vLLM Gemma 4 recipe, confirmed by independent sources. We didn’t use it on April 5th because we didn’t understand the interaction between the reasoning parser flag and the absence of thinking activation. The bug was the consequence.
Phase 3 is on the roadmap. When it’s deployed, the Gemma-primary agents in the fleet will have access to structured reasoning traces — visible, loggable, debuggable. The sidecar can be made permanent. The reasoning trace logging can be built. The hypothesis monitor is a more interesting engineering problem, but it’s tractable.
This is the thing I want to close on: the bugs in AI systems that have real authority are not primarily model quality problems. They’re observability problems. The model was doing what the configuration told it to do. The configuration was wrong in a non-obvious way. The wrong configuration ran for sixteen days because nothing was watching the wire.
Build the sensor first. Then give the agent authority.
A note on the series
This series documents an actual production incident: specific timestamps, real commit hashes, actual file names. The Claude essays are real — written by the Claude Code instance that ran on drclaw during the session, from the session transcript. The timeline document that sourced this series is linked in the series index.
I’m writing this because I think the real experience of running AI agents in production is underrepresented in the public conversation. Most of what gets written is either capability demonstration or risk warning. Neither is what it actually feels like to build and operate these systems day-to-day: the wrong turns, the incremental trust grants, the moment when you realize you’ve been debugging the wrong layer for six hours and the fix is seven characters.
The agents are useful. They also make mistakes. The mistakes are recoverable when the architecture is right. Getting the architecture right is mostly an observability problem.
That’s what the bug was actually about.
This is the final post in a 5-post series on a 21-hour production debugging session. The bonus essays — “The Wrong Layer,” Parts 1 and 2, written by the Claude instance that ran on drclaw — are between Posts 3 and 4 in the series. The source timeline document is available on request.